因为对数学感兴趣,勇敢的少年决定投身 Kaggle。
知乎上有这样一个问题已经收到了超过 700 条回答。

在这之下有人冷嘲热讽,有人给出了鼓励和建议。从人们回答的时间来看,问题的发起应该是在 2017 年,14 岁的少年如今也到了上大学的年龄。不知他 or 她是否还能坚持自己的兴趣和理想?
正如很多人所说的,如何让自己的兴趣转化为事业要看自己的努力。最近在机器学习圈里,就有一个 14 岁靠一己之力成为著名数据竞赛平台的冠军。
他叫 Andy Wang,是一名来自美国华盛顿州 Redmond 的华裔,最近刚上高一。他向我们介绍了自己如何从零开始,成为 Kaggle 竞赛冠军的心路旅程。
人们可能觉得「数据科学」和「机器学习」这些术语令人生畏,需要足够的专业技能才能把握。如果你简单浏览一下数据科学和机器学习领域也会得出这样的结论,盯着无穷无尽的代码和技术术语,经常让人不知道从哪里开始。
Kaggle 是许多人开始旅程的地方之一,如果你不知如何入坑,Kaggle 是投入竞争,赢得声誉和深入机器学习领域的好地方。
在本文中,我将带你了解如何在 14 岁时成为最年轻的 Kaggle 竞赛大师之一。
Andy Wang 是谁
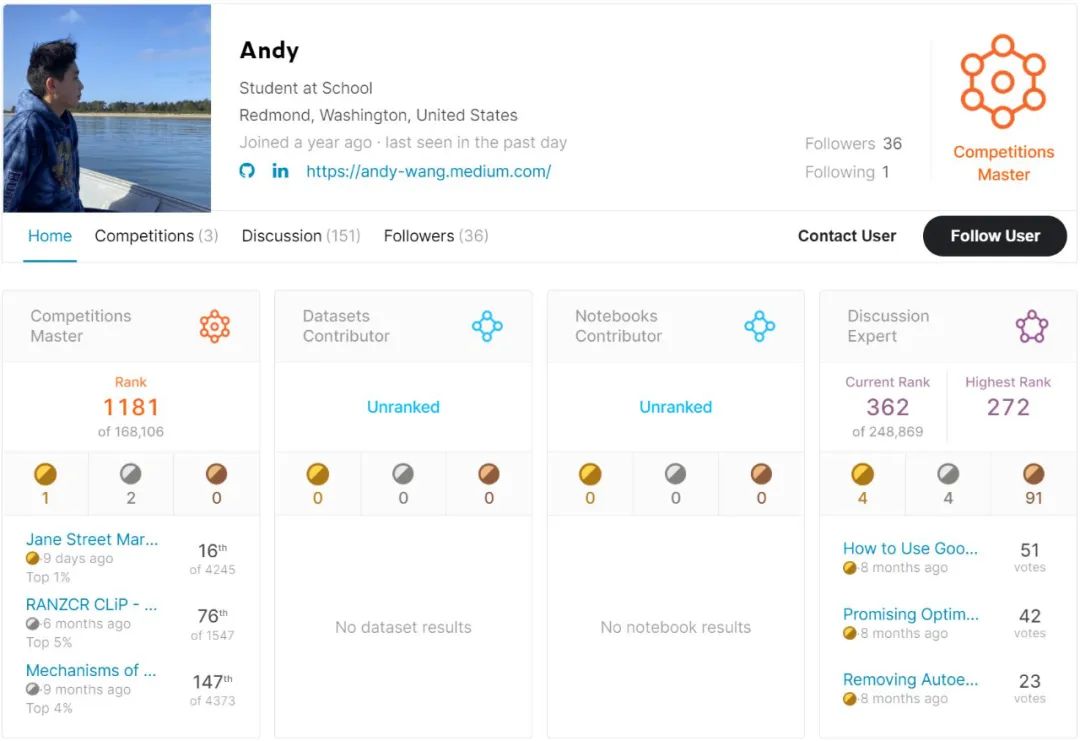
Andy Wang 来自美国华盛顿州 Redmond,现在是一名高一学生,对数学、人工智能和计算机科学较感兴趣。他此前曾在 Kaggle 平台上获得了一枚金牌和两枚银牌。

早期经验
几年前,我开始对数学感兴趣,并开始自行学习超过学校课程内容的知识。没过多久,我就把目标转向了编程,因为我从小就对计算机科学着迷。经过对于在线课程的一番搜索,我找到了几门 Python 基本编程和概念的课程并开始学习。不久以后我就制作出了一些基于回溯算法的小项目,比如数独求解器。
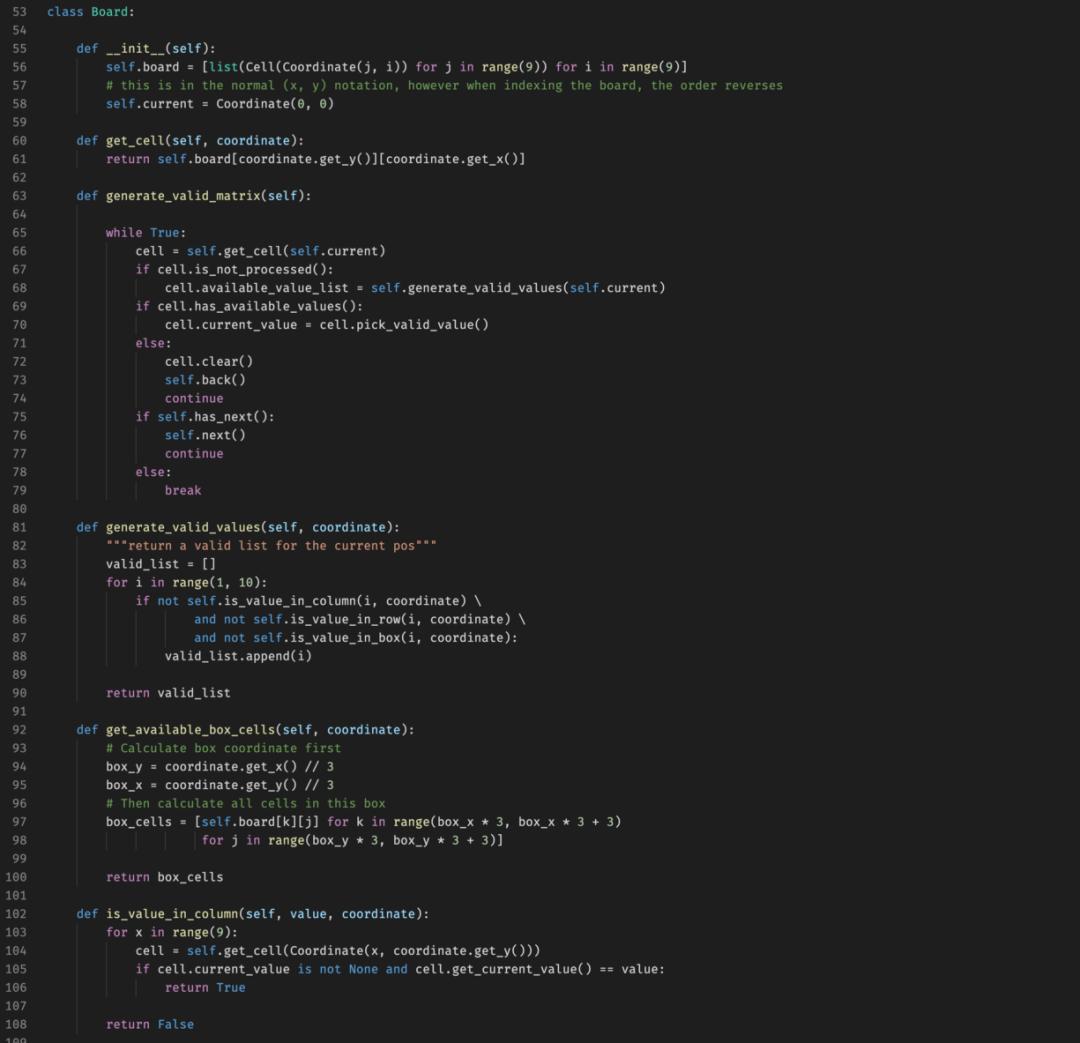
数独生成器的代码。
此时我开始对学到的知识该用来干什么有了疑问。直到有一天,当朋友向我介绍机器学习和数据科学领域时,我才真正为它的力量感到惊讶。我得知了 Kaggle,这是一个数据科学竞赛平台,它扩展了我对当前计算和人工智能技术的可能性的认识。
我是如何进步、如何学习的
我对编程知识和机器学习的了解大部分来自互联网,当你有疑问时,互联网是你最好的老师。没有学校教授数据科学或者神经网络,如果想要在 Kaggle 竞赛中取得成功,你必须依靠自己。
对于很多人来说,数据科学和机器学习是一项比较难的任务,即使是有了资源和课程,也有人不知道从哪里开始学起,如何学习。因为有许多领域与数据科学和机器学习相关,而精通每一个领域是不可能的。数据科学和机器学习功能强大,对于像我这样的初学者来说,你需要找到你感兴趣的东西,并充分挖掘它的潜力。
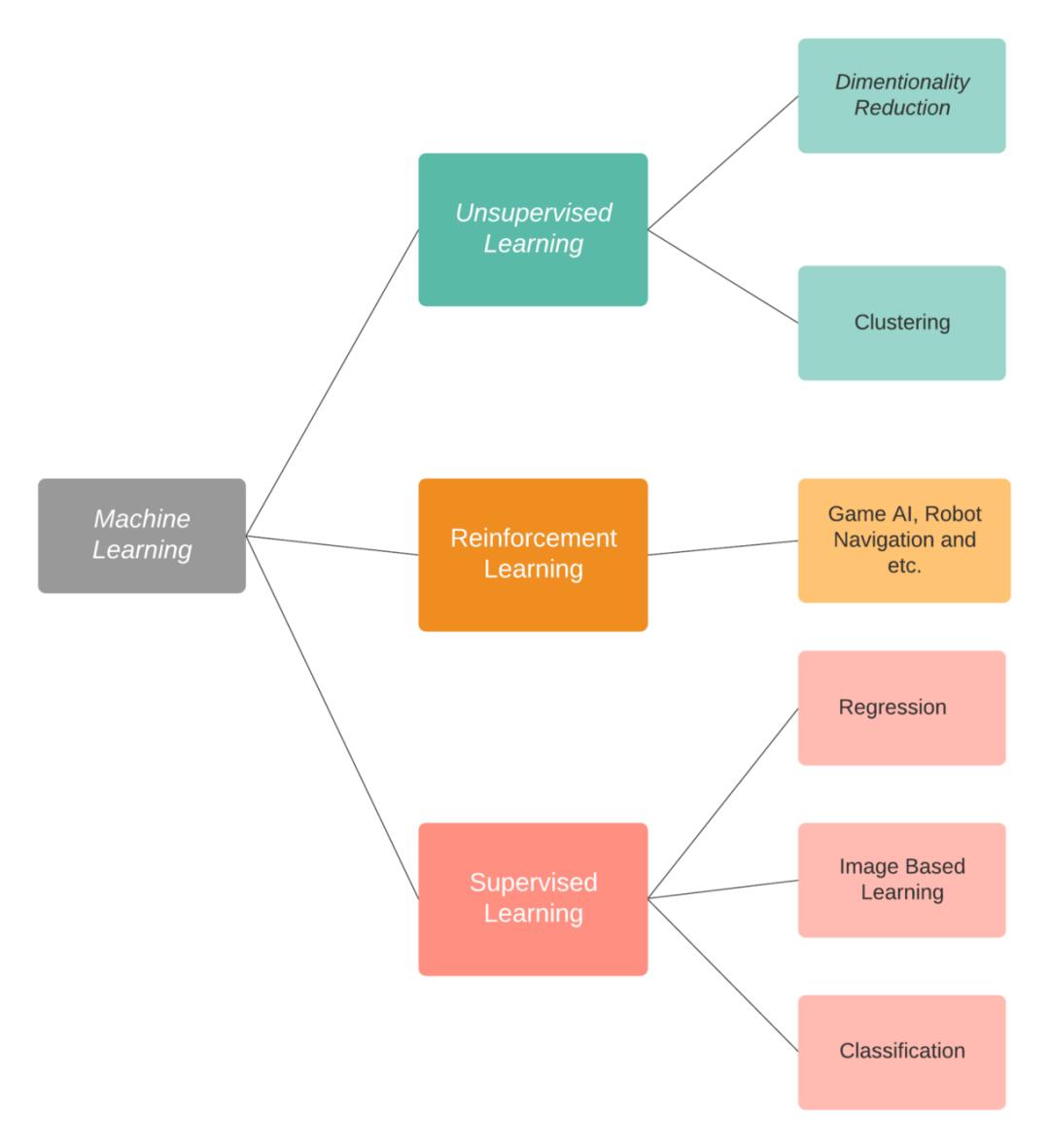
机器学习的不同领域。
对于很多人来说,由于先前知识的积累,学习数据科学和机器学习方法有所不同,下面是我成功的路径:
数学是一切的基础,线性代数和微积分是使用的机器学习中最重要的概念。几乎所有的机器学习算法都以这样或那样的方式与这两个领域相关。数据以向量和矩阵的形式表示和处理,因此,理解矩阵的基本运算是必要的。在机器学习中,微积分最常见的用法之一是梯度下降。梯度下降是一种算法,通过使用函数的梯度迭代一步步逼近全局最小值来最小化目标函数;
统计也非常重要,顾名思义,数据科学是关于数据的。虽然计算机可以预测数据的某些趋势,但只有人类可以分析它们,计算某些属性,并最终对数据得出结论。数据的预处理和特征工程在很大程度上依赖于统计学。我零碎地学习统计学,从网上搜集资料,寻找合适的在线课程;
在了解了基础知识后,我开始着手编写代码。有了面向对象编程(OOP)和 Python 的基础知识,我找到了在线课程,教我机器学习中常用的库。与简单地遵循代码和复制粘贴不同,我确保自己理解了代码背后的数学原理。如果你不了解代码的内在运作,你就不可能充分利用所学知识。我从简单的算法开始,例如线性回归,到更复杂的算法,例如神经网络。
一点一滴的学习,积少成多,一开始学到的简单知识,将来可以轻松积累成复杂的知识。
参加 Kaggle 竞赛
我参加了使用回归技术预测房价的初学者竞赛。我发现我学到的东西远远不够,我最缺的是经验。最好的学习方法是通过失败和经验来学习新的东西。我熟悉了 Kaggle 环境,并且浏览关于 Kaggle 的问题讨论和笔记。不久之后,我觉得我已经为第一次真正的竞赛做好了准备。我和我的朋友 Andre Ye 一起参加了 Mechanisms of Action (MoA) 竞赛。
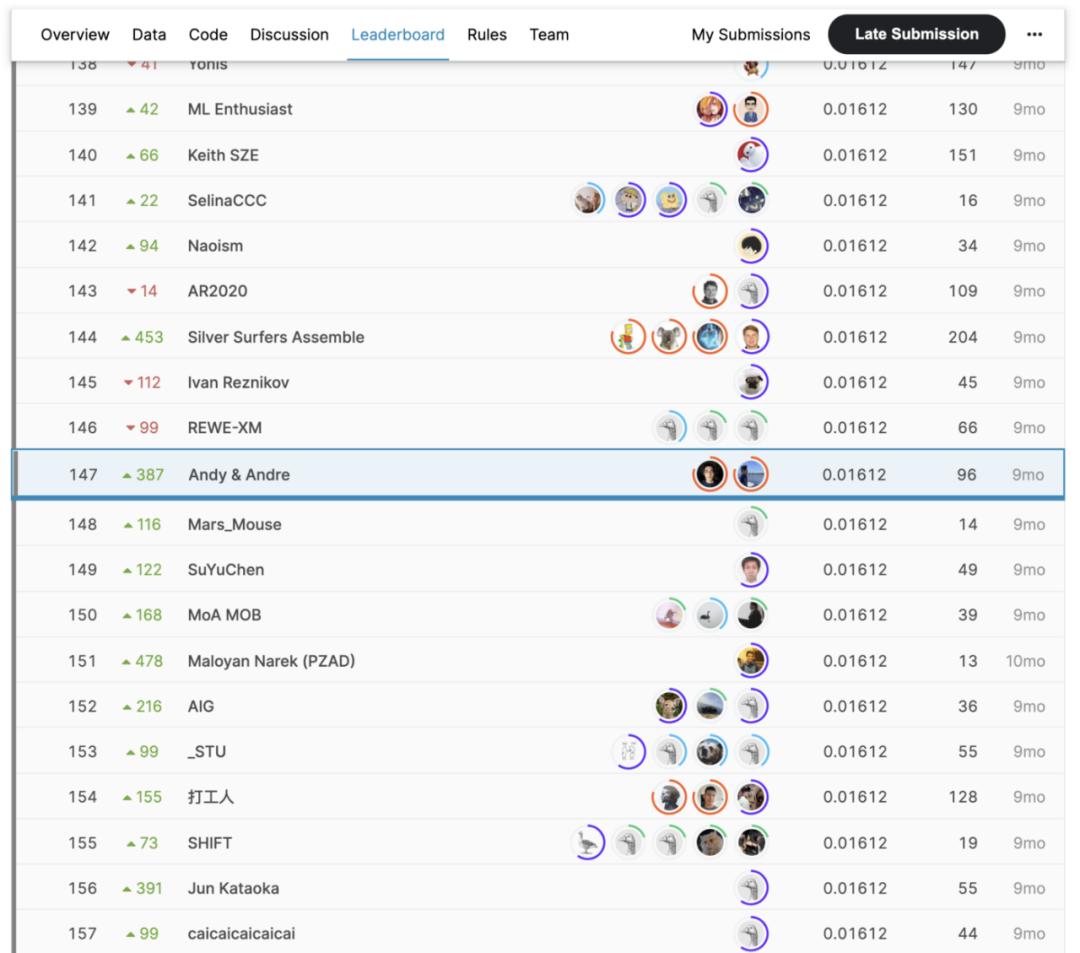
我们的第一次 MoA 竞赛。图源:https://www.kaggle.com/c/lish-moa/leaderboard
当时我们都是比赛新手。论坛上所有看起来很专业的代码和技术讨论让我们很惊讶。我决定从头开始,在讨论帖的帮助下,我能够在短时间内建立基线。创新对于在竞赛中取胜非常重要。我仔细研究了与 MoA 问题相关的论文和文章,然后与论坛上展示的方法相结合,使我们的解决方案进入了前 4%。之后,我们有了更多经验,又参加了另外两个竞赛,分别取得了银牌和首个金牌。竞赛结果出乎我的意料之外,非常感谢从 Kaggle 社区获得的指导。
下面将介绍一些我参加 Kaggle 竞赛中观察和学习到的技巧。
我在 Kaggle 竞赛中遵循的通用 pipeline
从自己参加过的 Kaggle 竞赛中,我始终遵循一个通用的 pipeline,它不仅可以将工作组织得当,还能高效地产生有意义的结果。
仔细阅读数据描述和概述。如有可能,可以稍微探索领域知识;
在阅读任何论文、讨论或笔记之前,尝试自己创建一个基准。这样做可以使你的思维不宥于他人的观点,并产生一些全新的 idea;
制定一个可行的交叉验证策略并提交至排行榜。确保自己的交叉验证策略同样适用于排行榜非常重要。
阅读和学习。全身心地投入到与主题相关的论文中,并从论坛和公开笔记中汲取灵感;
在模型或特征层面对基准进行调整。每次只调整一个内容,这样就知道模型提升或表现更差的原因是什么;
尽可能多地探索新方法,不要将时间和精力浪费在无法发挥作用的内容上;
集成。如果一切别的 neirong 都不起作用,集成或堆叠则可能是实现提升的最稳健方法;
提交结果时选择具有好的交叉验证分数的,并确保自己知道它为何表现良好。
我学到了什么、使用了哪些技巧?
随着参加了越来越多的 Kaggle 竞赛,我对一些解决方案的复杂度感到惊讶,从特征工程到神经网络架构,等等。
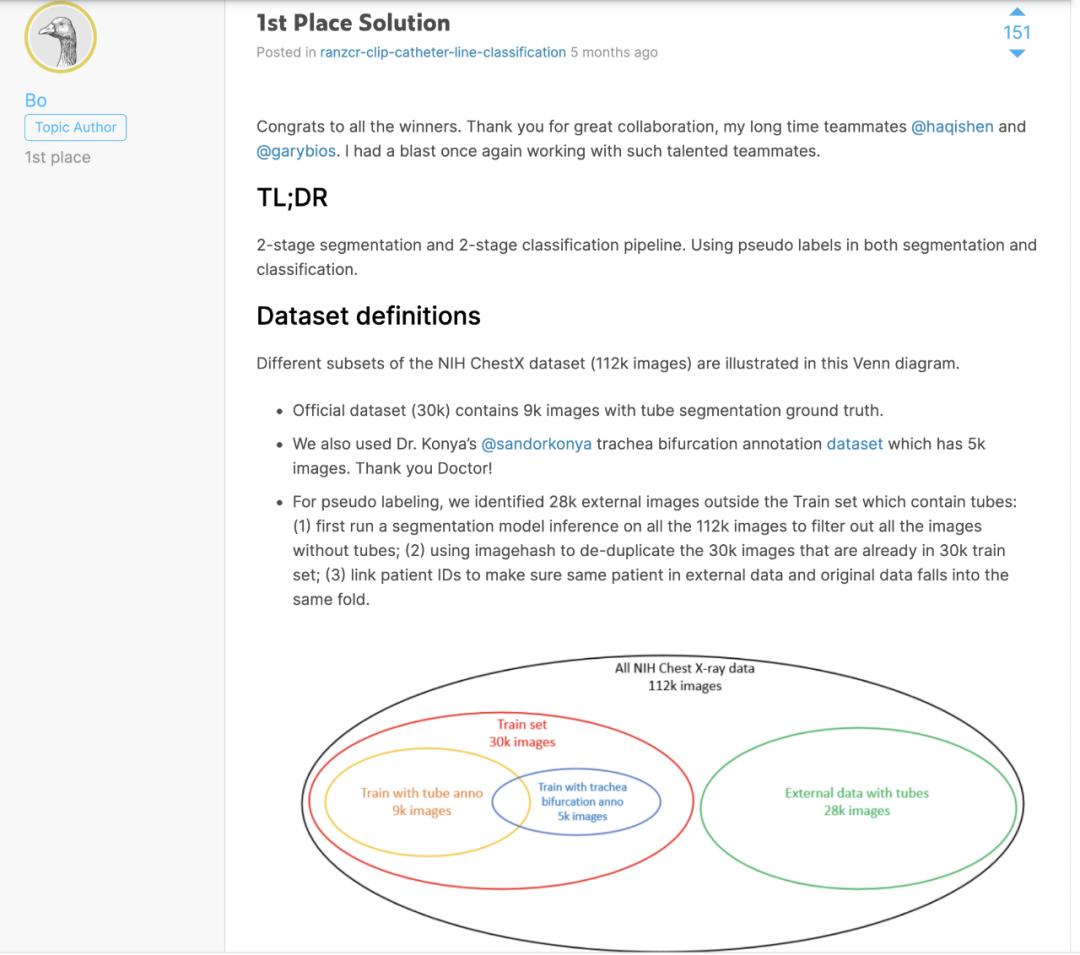
RANZCR CLiP-Catheter and Line Position 挑战赛(医学影像插管分类)中的第一名解决方案。
通常而言,机器学习算法仅能从信息性数据中很好地学习。能够使用与预期不同的算法在某些情况下可以提供帮助。比如,使用主成分分析(PCA)算法降低数据维然后将简化后的特征连接回原始特征,这种做法已经多次帮我解决了问题。
特征工程带来了特征选择。删除不重要的特征有助于减少数据中的噪声。在 MoA 竞赛中,论坛和讨论帖中提供的方法对我们设计的模型没有帮助。在这些情况下,要敢于深入阅读和研究论文。在我当时正在参加的这个竞赛中,多标签分类并不常见,我也没有找到任何简单的教程。最后,我找到了一篇使用问题转换来比较多标签特征选择的论文。
阅读论文看起来可能令人生畏,但快速浏览论文并从满篇的专业术语中找出关键词是一项至关重要的技能。对于像我一样的初学者而言,试图理解所看论文的方方面面是不可能实现的。只有当我找到自己需要并且要用到的论文时,我才会努力理解论文中的每个单词和参考文献。
在建模时,我最大的体会是要有创造性。这种创造性不仅体现在模型结构上,在模型如何能够作用于不同类型的数据这一问题上也要有创造性思维。
稍微调整模型使其具有非线性拓扑结构或者为表格数据创建类 ResNet 结构的网络。这样做取得了意料之外的结果,在 MoA 竞赛和 Jane Street Market Prediction 竞赛中,我们在 4,200 个参赛团队中排名 16 位;
探索去噪、变分和稀疏编码器等不同类型的自编码器可以为数据带来意想不到的变化,远远超出了简单特征工程和选择所能实现的结果;
集成。结合不同模型的结果可以增加解决方案的多样性,使其更加稳健和稳定。不管建模技巧起到了什么作用或者没起作用,集成往往是我在竞赛中的最后杀手锏;
实时关注新论文,并探索论坛中没有提到的内容。稍稍改进激活函数(尝试以 swish 替代 ReLu)和优化器(以 AdaBelief 替代 Adam 等)或许可以从模型中「榨出」一些额外性能;
不走寻常路。使用 1D CNN 在表格数据上执行特征提取,或者利用 CNN 的优势,使用 DeepInsight 将表格数据转换为图像。
图源:Kaggle
最后,在一场竞赛中发挥作用的策略不一定能够提升另一场竞赛中的解决方案。在 Jane Street Market Prediction 挑战赛中,我发现特征工程对竞赛结果毫无帮助,但在建模中发挥奇效。需要牢记一般经验法则:
在这些情况下,不要纠结于一些「以往竞赛中有效」或「对其他竞赛有效」的解决方案,要向前看,并花更多时间探索那些可以带来提升的新东西。
参加 Kaggle 竞赛并拿到奖牌并不容易,但使用正确的学习方法与工具可以令过程更加容易。
浏览讨论帖和阅读公开的笔记非常有用。新的 idea 每天都会出现。我就从论坛中提到的论文以及公开笔记中使用的库中了解到了一些最新、吸引人的模型和工具。以 TabNet 为例,它是一种建模表格数据的新方法,使用序列注意力合并模型内部的特征选择。借助 TabNet,我在 MoA 竞赛中拿到了银牌;
创建一个稳健的 pipeline 对于在最终的私人排行榜中取得好成绩最为重要。将时间浪费在过拟合以在公共排行榜中额外获得 .0001 没有意义。始终信任自己的本地交叉验证分数,因为训练数据的数量大于公共排行榜的数量。
在设置本地交叉验证方案时,需要记住以下几点:
Fold 数值>3。当 fold 数值越低时,训练分割(training split)将不足以表示整体数据;
确保数据不出现泄露。尤其是在时间序列预测等情况下,常规交叉验证会导致未来数据的泄露,应该使用某种形式的序列分割;
当目标不平衡时使用 Stratified KFold,这种方法能够在多个 fold 中平均地分割目标;
确保自己知道为什么会出现提升。这一点非常重要,因为随机种子和其他未知因素都可能影响到结果。这也可能导致未见过数据中出现显著不稳定性。
总之,仅靠「别人怎么做,自己就这么做」对学习或者赢得竞赛没有帮助。我从 Kaggle 竞赛中收获的最重要的经验是永远不要抄袭他人的工作。我可以从他人的 idea 中获得启发,甚至使用他们的建模方法,但从未将他人的工作当作自己的解决方案。当接触新内容时,我养成了一种习惯,即查阅自己无法理解的所有内容,直到可以向他人自信地解释这些内容。
本文来源于网络,如果侵权立删,操作:浩宇科技,如若转载,请注明本文地址:https://www.86376.net/gedi/756922.html

