郭敬明终于道歉了。
2020年12月31日零时,郭敬明就当年小说《梦里花落知多少》抄袭庄羽的作品《圈里圈外》一事在微博上道歉。
同时郭敬明还表示,将把《梦里花落知多少》的版权收入全部赔偿给庄羽女士,“如果庄羽女士不愿意接受,我会把这笔钱捐给公益慈善机构”。
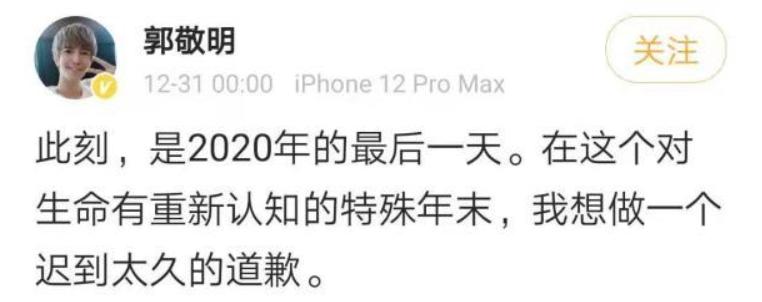

郭敬明道歉后,庄羽也很快进行了回应:时隔十五年,收到郭敬明的道歉,如郭敬明先生所说,这的确是一份迟来的歉意,我接受郭敬明先生的道歉。
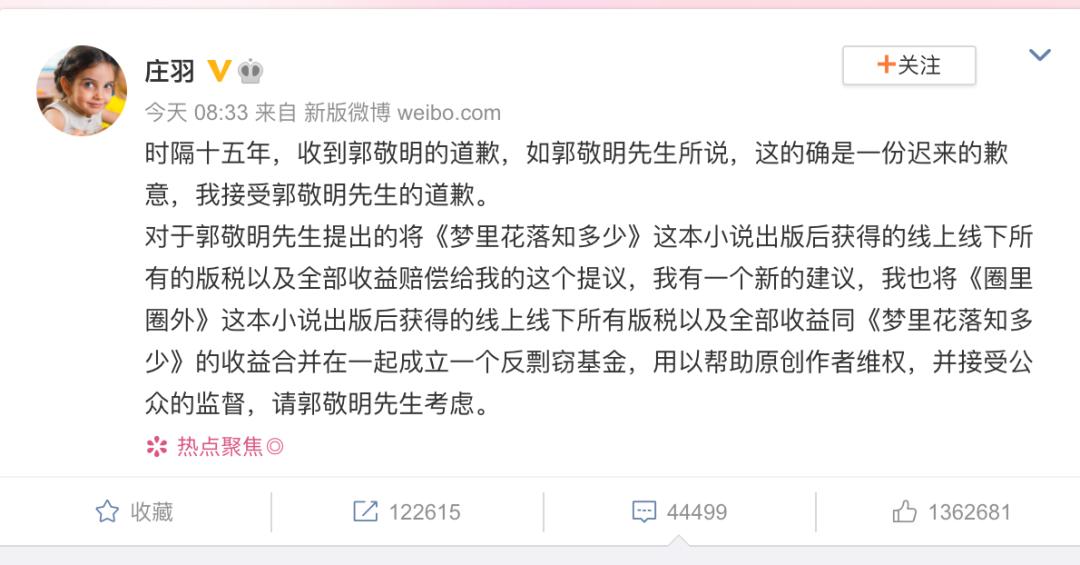
除了接受郭敬明的道歉,庄羽还提议将《圈里圈外》这本小说出版后获得的线上线下所有版税以及全部收益同《梦里花落知多少》的收益合并在一起成立一个反剽窃基金,用以帮助原创作者维权。
至于具体的维权方式,尽管庄羽没有表示,但可以想见只可能是用于支持原创作者在发现别人抄袭自己后,维护自身权益的各种举措。
而以目前的网络文学数量来看,原创作者最需要的——也是最难的一点——是及时发现自己被剽窃了。
如果只是靠人力,多大规模的反剽窃基金都很难做到及时发现剽窃现象。
那这事儿,能不能靠AI?
AI 反剽窃,并不容易
一提到反抄袭、反剽窃,我们的第一反应一般都是论文的自动查重系统。无数学子都曾在“降重”(降低重复率)的路上被论文查重系统按在地上反复摩擦。
传统的论文查重系统并不能称为现在意义上的AI,比如我们熟知的知网论文查询,就是以连续十三个字符重复为原理,通常是以句子为单位,就是说一句话当中如果有连续十三个以上含十三个字符重复的,则该句被判定为重复率的概率就比较高。
但是这一呆板系统有着明显的缺陷,简单的更换同义词、更换语序就能很大程度上避开这种查重。
这就涉及到了NLP领域一个非常有意思的领域——文本语义相似度计算。
举个例子,智能客服如何理解人类针对同一个问题的同一个提法?
“花呗如何还款”&“花呗怎么还款”
“花呗如何还款”& “我怎么还我的花被呢”
“花呗分期后逾期了如何还款”&“花呗分期后逾期了哪里还款”
对AI来说,理解这些相似的问题并不容易。从传统的特征工程方法,到现在的深度学习方法,这一问题都没有得到很好的解决。
Kaggle针对这一问题也有一些比赛,主要是针对搜索引擎和QA系统,这也侧面说明了目前AI连单个句子的相似性分析都很难准确判断,更别谈对整个文章甚至书籍相似度的剽窃判断了。
更何况,即使往后AI解决了文本语义相似度的问题,抄袭者如果在文学作品中只抄袭故事架构和情节,AI想要判断就难上加难了,这个难度甚至超越了AI对于语义的理解,上升到了AI对人类复杂社会和情感关系的理解。
当然了,如果是直白的抄袭,改写都懒得改写,那么最简单的查重系统都可以查出来,比如下面这个。

反剽窃不行,AI剽窃却很在行
AI是把双刃剑,这句话用在剽窃和反剽窃上太合适不过了。
尽管刚才说了目前AI剽窃可能还不能做的很好,但是剽窃这事儿,AI现在却很在行。
在百度上随便搜一下,都能搜到一些可以用AI洗稿的工具,号称可以通过AI识别他人的原创文章,然后通过改写生成一篇“伪原创”的文章。
就针对上面那句话,文摘菌找了一个有线上版本的AI智能改写工具试了一下。顺便看了看工具的介绍,上面列举了几个耳熟能详的NLP技术:情感分析、信息分类、实体识别。
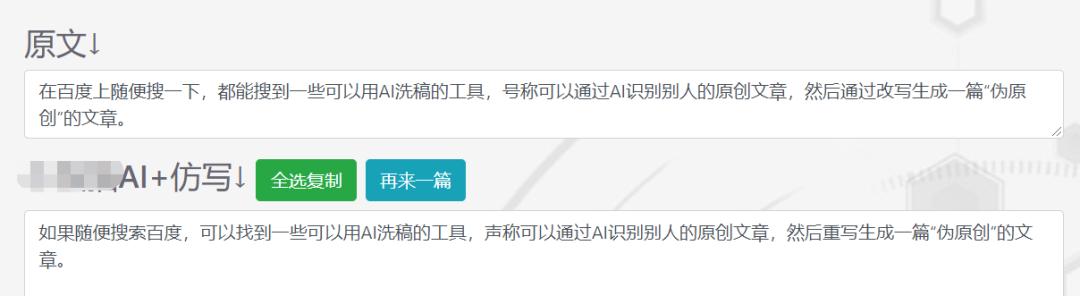
这么一看,效果貌似还行,但还是很容易就看出来是改写的,比如第三句只是将“号称”改成了“声称”。
也许这种改写工具很难对付严格的学术审查,但是对付像微信公众号原创校验这样的反抄袭机制呢?
我们不妨来试试。
首先选择一篇文摘的原创文章,然后进行改写。
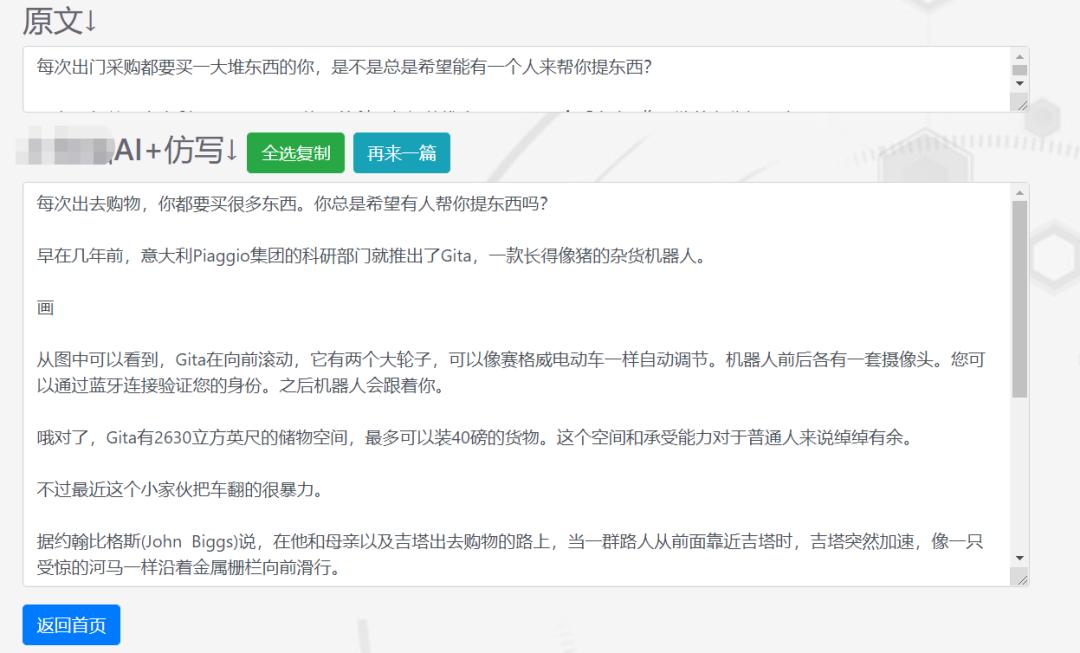
之后我们再将改写后的文章复制到后台发送,看能不能通过原创校验。
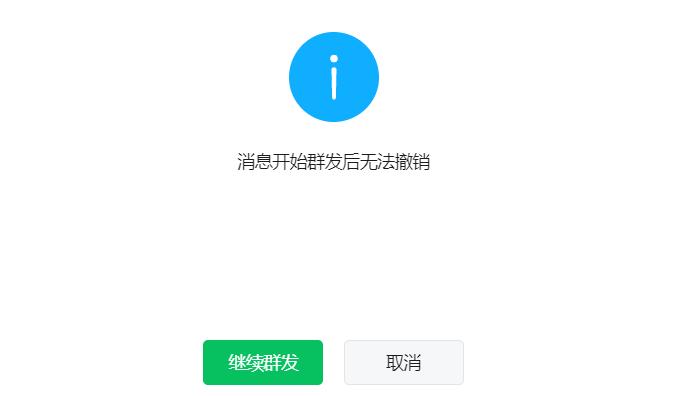
点击发送之后,微信公众号后台并没有弹出原创校验不通过的选项,而是可以直接发送。
很显然,至少这个工具可以成功剽窃微信公众号文章而不被原创校验机制发现。
这么看来,难道AI真的有点不厚道,反剽窃不行,剽窃却很在行?
小伙伴们,你们怎么看?
本文来源于网络,如果侵权立删,操作:浩宇科技,如若转载,请注明本文地址:https://www.86376.net/gedi/24111.html

